Backpressure for dummies
A toy example showing how lacking backpressure may lead to failures and how to add it.
A possible pattern for replicating programmatically AJAX POST requests when scraping webpages using Scrapy
Have you ever tried to scrape a data point whose value changed with changes in other options available on the webpage? In this article I am going to show a possible pattern for scraping all the values available when these are retrieved through AJAX requests.
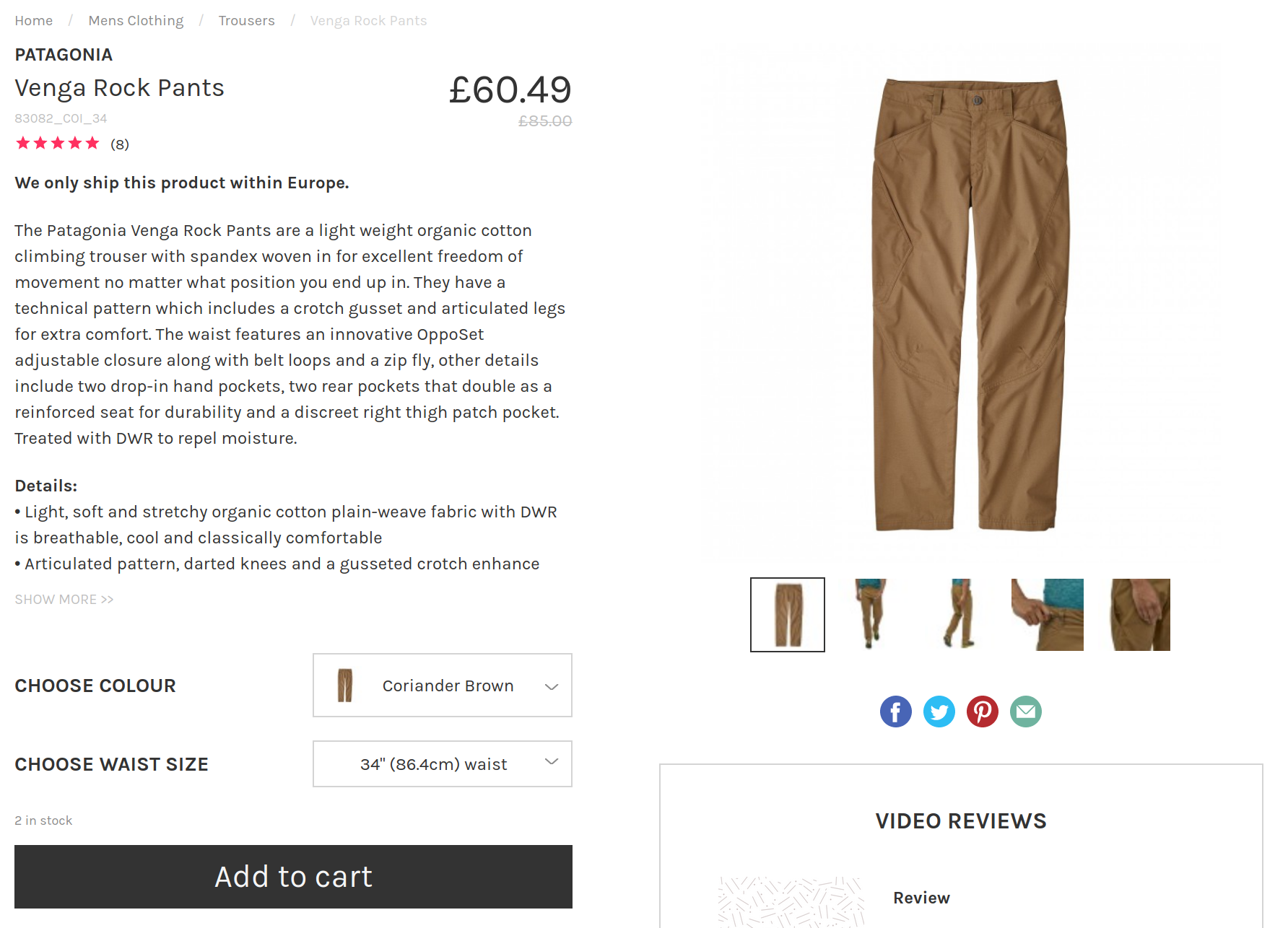
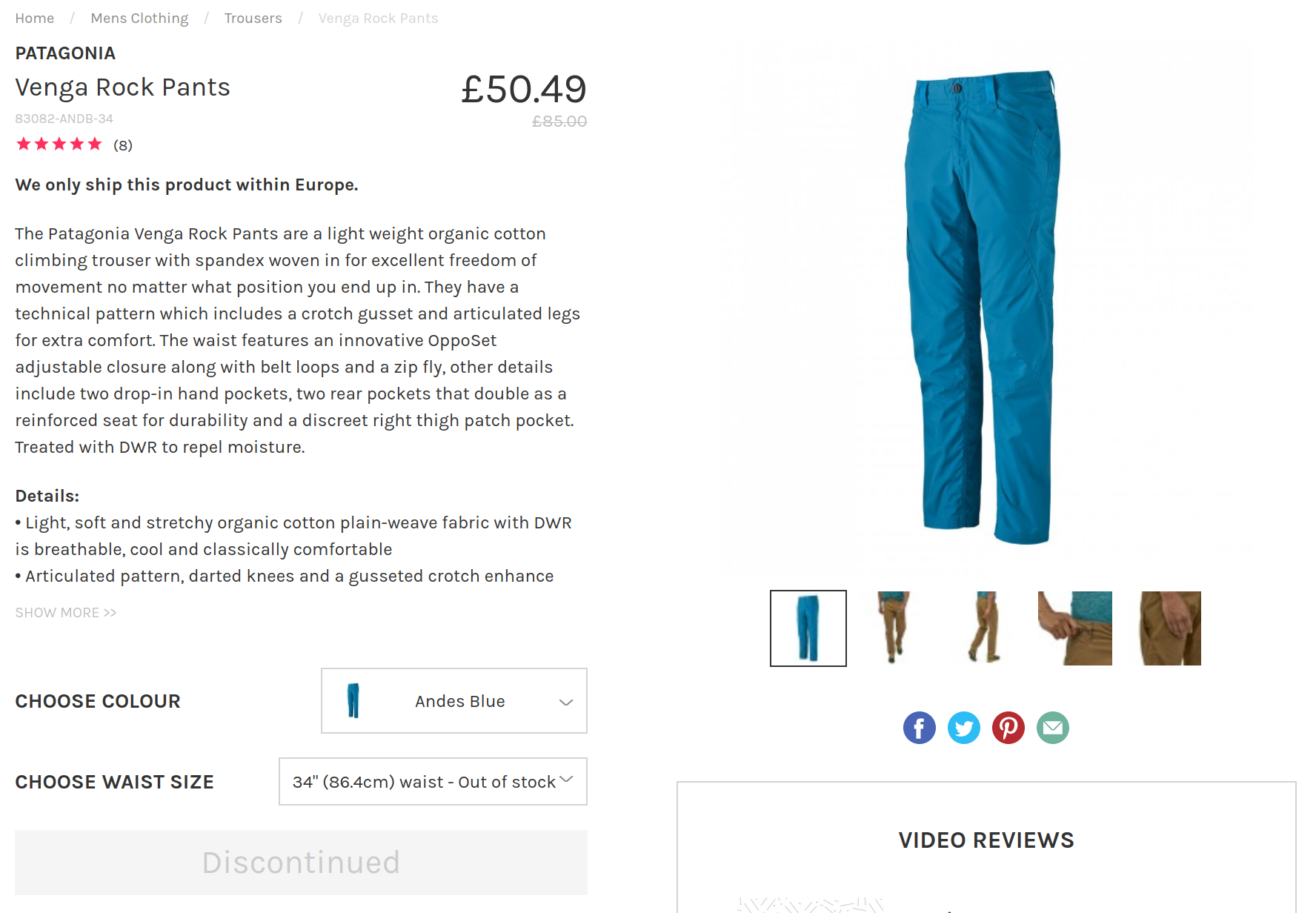
More specifically I found myself using this pattern while building smarthiker.co.uk, a price comparison website for hiking, climbing and mountaineering products. While scraping products details I realised that the price for the same product may change for a different colour or size. The two pictures below (which are made up) should give you an idea of what I am talking about.
Scrapy is a python library making available an easy to use framework for scraping websites. One of the main components of the library is the Spider class. Through this it is possible to specify from what URL to start spidering the website, how to parse the HTML pages retrieved, and possibly send other requests from them.
I will dare to claim that usually when scraping an e-commerce website the final goal is obtaining one object (an Item in the Scrapy framework) per product sold containing all the details of interest. Therefore, the final yield statement, the one not leading to further requests, should return all the scraped data for the single product considered.
Below you can find some python pseudo-code for a spider scraping the hiking e-commerce website BananaFingers.co.uk. Using a series of brand-specific pages, presenting each a paginated list of products, it should be possible to get all the products available on the website. The code below is a simplified version of the one used in production and it is only meant to make it easier to understand how to spider the website, not to actually spider it.
So, using a modified version of the snippet above you should be able to successfully scrape all the products sold on the website. However, only one price is scraped for each product, the one charged for the default colour-size combination loaded on the webpage. In order to get the specific colour-size combination prices you need to replicate the AJAX requests sent for each combination. When you pick a colour from the pick-list on the webpage an AJAX POST request is sent and the price value is updated on the page. So, to get the full picture we need to send as many calls as colour-size combinations available and somehow return their results with the original response for the product page.
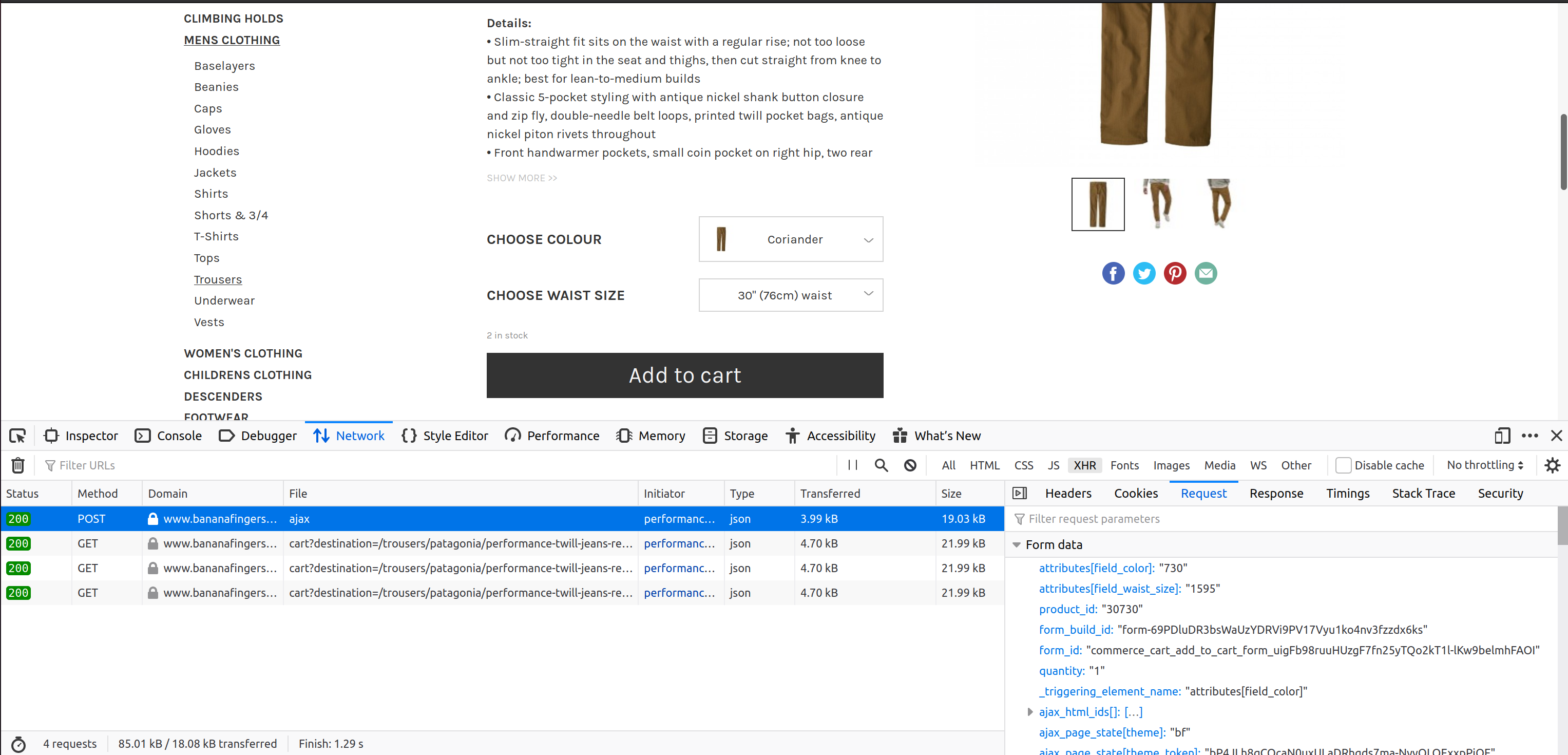
Using your preferred browser development tools It should be relatively easy to see the POST request specifics (target URL, payload, etc). As you can see in the picture below we can easily access the payload content and get a feeling of what we will need to change to get the colour-size prices. In this case, we need to specify the field colour, the size, and the product id.
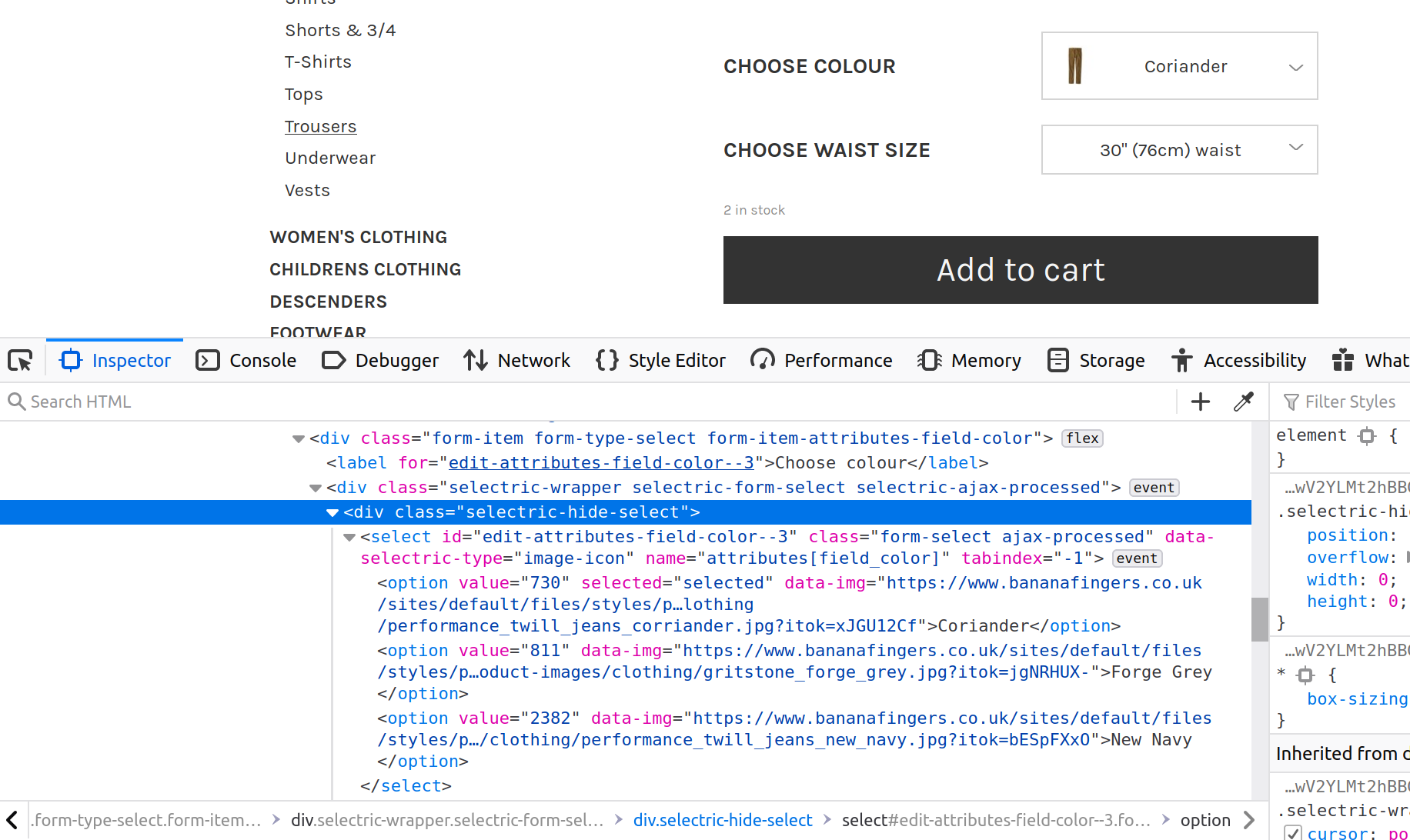
The product-specific POST request payload keys and values (“attributes[field_waist_size]”: 1595, “attributes[field_color]”: 730), can be automatically scraped from the DOM. As you can see in the image below, the key for the colour/size field is available at the “name” attribute in the “select” HTML element. While the value can be accessed using the “value” attribute in the “option” HTML element.
Once you have obtained the key/value pairs for all the options available it should be relatively straightforward to create a list of possible combinations and assemble the needed payloads for each combination.
Now we should have a list of key-value pairs that can be used as payloads for the different post requests we will send. Now we will send the requests and store the results somewhere so that they can be returned with the final item.
I personally think that the most convenient way of getting all the colour-size prices for a product is sending the POST requests sequentially, carrying over the prices fetched for each combination, and once the list of combinations is exhausted return the item with the original product page HTML and the list of prices fetched. Alternatively, we could be yielding for each POST request an item with the original HTML and relative price returned, and then merge the all the items for a product further down the pipeline.
In the first case, for each POST request, we will wait for the response (and parse it) before sending the next one. While in the latter case the requests will be all sent roughly at the same time (eg through looping over the iterable containing the payloads) and each response will be parsed independently from the others whenever returned. The extra waiting time of the first approach will probably make it take longer than the first one when spidering the whole website, although I haven’t tested this.
If we want to go down the first route we can use the cb_kwargs argument in the Request to carry over all the product details to the response. So, we will be able to carry along the list of prices already obtained, the list of payloads we still need to send, and the HTML for the original page. The pseudo-code below should give you an idea of a possible pattern to do that.
As shown in the snippet above the parse_product_item is called as soon as the product page is reached by the spider. If this is the first time the method gets called for this page the response_params_for_post list won’t exist, so it will be created and filled with the list of payloads that should be sent for each POST request. Alternatively, if the list already exists, the next element will be popped and used as payload for the next POST request whose response will be parsed again through the parse_product_item method. This process will continue until the list of payloads for the POSTs has been exhausted. At that point, the original HTML body will be passed with all the fetched prices to a custom ItemLoader, so that the values for the item will be extracted.
To summarise, going through the steps below is possible to fetch the values loaded through multiple AJAX calls triggered by interactive components:
This is probably one of the most interesting scraping problems I worked on while building smarthiker.co.uk. I was quite surprised that the same hiking/climbing/mountaineering product may be sold at a different price depending on colour or size. Still, whether this is surprising or not a robust price comparison website should be able to handle these situations as well.
A toy example showing how lacking backpressure may lead to failures and how to add it.
A simple piece on how to patch objects and use pytest fixtures in tests at the same time
Using various tools to make python environments working automagically also with emacs
On the benefits of documenting your work and how it can impact your share of the pie
Looking back at 2021 to look forward at 2022
Several ideas worth remembering from Sandi Metz’s book 99 bottles of OOP
Can we do better than a straightforward pickle.dump?
Why interviewing time to time is useful and what I learned so far by doing so
Interesting readings of the month
Interesting readings of the month
Use case of the Strategy pattern in a data science application
Interesting readings of the month
Considerations on how practicing writing can help improving how we communicate and how we think
an overview of what eigenvectors and eigenvalues are and why they make PCA work
A possible pattern for replicating programmatically AJAX POST requests when scraping webpages using Scrapy